MACHINE LEARNING
Machine learning is basically about the science of giving computers the ability to learn and it is being used daily in our lives through various significant applications such as self-driving cars, speech recognition, searches, and recommendations. And let us tell you a fact. Machine learning is one of the most significant tech trends. It seems that AL and ML algorithms are presently being used in as many kinds of software applications as possible
TRAINING DATASETS
The training data set in Machine Learning is the actual dataset used to train the model for performing various actions. This is the actual data the ongoing development process models learn with various API and algorithm to train the machine to work automatically.
Use Of Data Set in machine learning
ML depends heavily on data, without data, it is impossible for an “AI” to learn. It is the most crucial aspect that makes algorithm training possible… No matter how great your AI team is or the size of your data set, if your data set is not good enough, your entire AI project will fail! I have seen fantastic projects fail because we didn’t have a good data set despite having the perfect use case and very skilled data scientists.
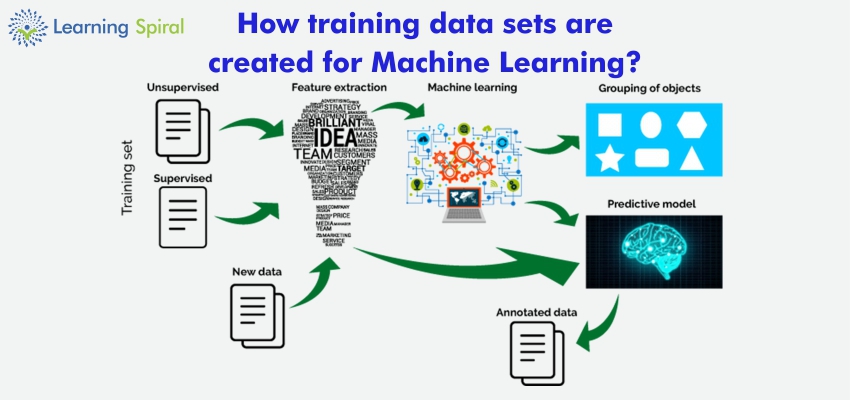
How training data sets are created for machine learning
Data Selection
Firstly, it is very important to opt for the right number of features for the particular dataset. The data should be accurate consistent and should have a very less number of missing values. As more missing values is not fit to be a part of the training set.
Data Preprocessing
After selecting the right data preprocessing is an important action to taken care of and that includes a selection of the right data from the complete dataset and building a training set. Here, some of the major steps are:
- Organize And Formatting Data
- Data Cleaning
- Feature Extraction
Data Conversion
- Composition: This step involves combining different features to a single feature for more meaningful & accurate data.
Quality Training data is paramount to the success of any AI model or project. Just imagine If you train a model with poor-quality data, then how can you get proper results? Quality Training Data + Machine Learning = Proper & accurate results.
The success of ML and AI models totally depend upon your Training Data
To power Machine learning we use Advance Data labeling Techniques that improve the quality of training data in an interactive manner after human correction takes Less time and greater output. Nothing is more essential than quality data in Machine Learning
ABOUT THE ORGANIZATION
One-stop Data Labeling and Annotation Service Provider. Learning spiral has a workforce with a diverse set of skills and the ability to deliver data annotation and data labeling at scale. We have a rich history of 10+ years of handling sensitive data on a large scale. Our affordable annotation services provided by trained in-house dedicated professionals ensure high quality labeled data to meet your needs. We are here to Empower your algorithm and bridge the gap between machines and humans with our reliable data labeling and data annotation services.
Pick the best Data labeling company for computer vision and NLP services while saving money and time!
Thanks for reading & Stay Tuned!